
こんにちは、GoodBrain web担当の宮島です。
前回のコラムを読んだ!自分でコードを書いてやってみた!実際に FocusCalm™ で測ってみてファイルを出力してみた!
…でも、 EEG ってどういうデータなの…?何か1つの箱に複数データ入ってる…?何これどうすんの?
そんなあなたへ!「分からない」で諦めて欲しくないから、データの整理方法と、Python での描画例をお教えします!
というわけで前回の初学者向けコラムの続きです。「まだ見てないよ」という方はこちらからどうぞ!
まだ脳波計測したことないよって方も、この機会に是非、一度触れてみてください!
目次
本日の目標
GoodBrainアプリから出力したCSVファイルのうち、 EEG を自分で描画してみよう!
上手くいくとこんな感じの画像が出力できます!
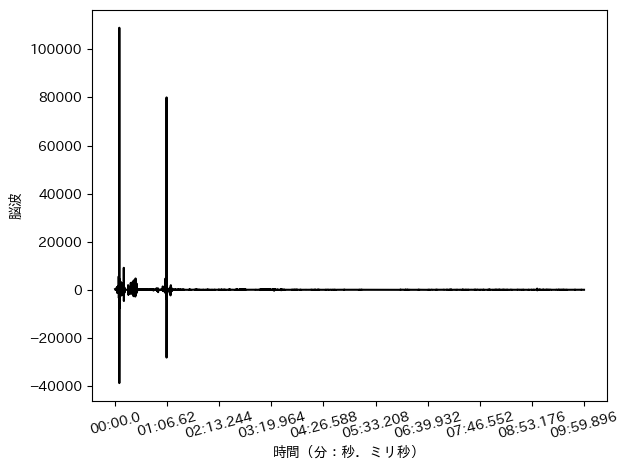

今回利用するツール
といっても、前回と一緒なんですけどね。
本日の主役
Python
現在最もメジャーで最も簡単な言語。なにより使いやすいのが特徴。また、いろんな人が使いやすくするための拡張機能(ライブラリ)を制作してるから、初心者でも超扱いやすい!
Pythonをサポートする、イカしたメンバー(ライブラリ)を紹介するぜ!!!
Numpy
Pythonが数学につよつよになるライブラリ。今回は数列を作成するのに用いる。
Pandas
表データを扱いやすくなるライブラリ。今回はCSVファイルの読み込みと、データの整形に用いる。
Matplotlib
データの描画を行なうライブラリ。今回は折れ線グラフを画像ファイル形式で出力するのに用いる。
補足:japanize_matplotlib
Matplotlibで図を出力する際、ラベル名に日本語を用いると文字化けしてしまう。これを解消するためのライブラリ。プログラミングって基本的に英語だからね…日本語対応してる方が珍しいんだよね…仕方ないね…
今回のPython実行環境
まぁ、これも前回と一緒なんですけどね。
Google Colaboratory
ブラウザ上でコードを作成することで、Googleのサーバで計算することのできるアプリケーション。お手軽で、Google側のマシンを用いるため比較的高速に動作する。上で述べたライブラリのうち、Numpy、Pandas、Matplotlibは初期環境の時点でインストールされている。まあ、簡単に言えば、Googleにコンピュータを貸してもらって、それを遠隔操作するって感じ。
そんなわけで、今回もGoogle Colaboratoryで実装していきます。
多分これが一番お手軽だと思います。
開き方、使い方は前回のコラム記事で紹介してます!
データの整理と描画
それじゃ、実際にコードを書いてみよう。
準備
今回もグラフを描画する際に index に日本語を用いるので、japanize_matplotlibをGoogle Colaboratoryにインストールしよう。
! pip install japanize_matplotlibを実行すると、以下のような実行結果が表示される。
Successfully installed japanize_matplotlib-“バージョン(’1.1.3′ など)”
と表示されればインストール完了!
インストールしたらインポートも忘れずに!
# 必要なライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
インポートが終わりランタイムに接続している状態で、ファイルをアップロードしよう。
アップロードが完了したら、pd.read_csv() を使ってCSVファイルの中身を変数 ‘df’ に代入しよう。
# GoodBrainアプリから出力したCSVファイルを、DataFrame型というデータ構造に入れる。
df = pd.read_csv("「実際にアップロードしたファイル名(.csvまで)」")
df
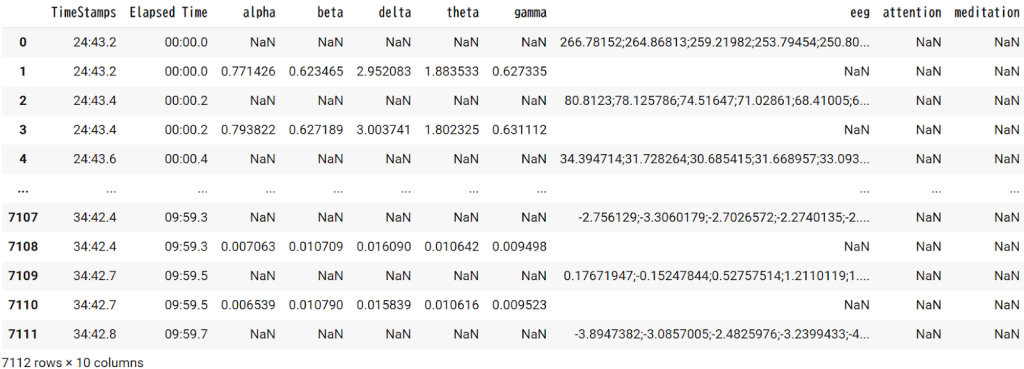
これでアップロードしたファイル及び変数 ‘df’ の中身が見れるようになった。
今回は「生波形と呼ばれる、電位の実測値」にあたる EEG を解析していく。
‘Elapsed Time’ の行と、EEG の行を用いる。
ただ、問題として、NaN と表示される、数値の入っていないところや、
1つの要素に複数の数値が入っているところがある。
このままでは解析することができないので、解析の前にデータの整形を行なっていく。
データの整理
以前描画したときと同様に
- loc[ ] を用いて変数に欲しいデータを代入する
- dropna() で NaN を削除
ここまでやってみると、EEG の行に、常に複数の数値が入っている事が分かる。
# 生波形の抽出
raw_data = df.loc[:, ['Elapsed Time', 'eeg']]
raw_data = raw_data.dropna()
raw_data
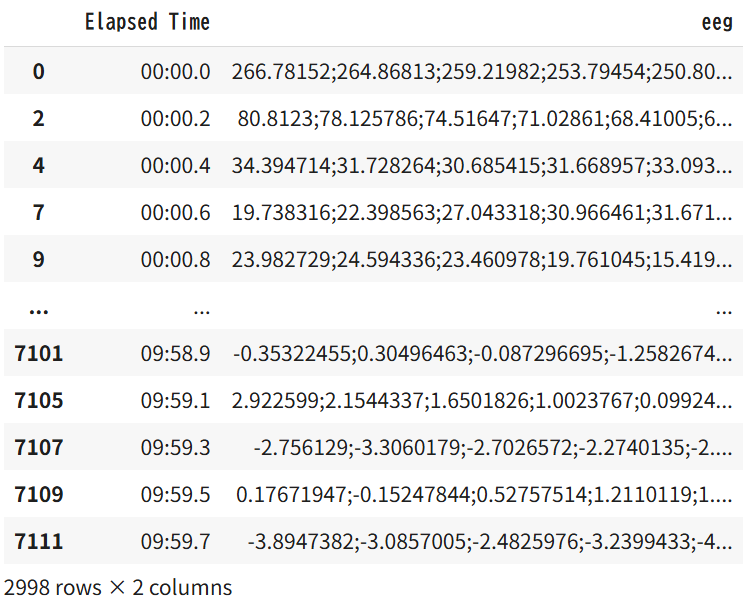
実は、1つの箱に50個の数値が、セミコロン(;)で分けられて入れられているのだ。
描画を行うには、
- 1つの要素に1つの数値が入っている。
- 数値が「str型」ではなく「float型」で表されている。
- 1つの数値に対して1つの時刻が、1対1で対応している。
という3つの条件を満たす必要がある。
まずは
「1. 1つの箱に1つの数値が入っている」と、
「3. 1つの数値に対して1つの時刻が、1対1で対応している」
を満たすために、データを1列にすることを目指そう。
最初に、1つの箱に入っている50個のデータを分割して50行にする。
実際にやってみよう。
データを取り出した変数の EEG という行に対して、
str.split() という、特定の文字列で分割する関数を用いる。
( )内に ‘;’ を入れると、セミコロンで分割することができる。
‘expand=True’ は行や列が増える事を許容する事を示している。
ここまでで以下のような感じ。
# 抽出データを1データずつに分割
df_raw = raw_data["eeg"].str.split(';', expand=True)その後、index を連番に戻すために reset_index() を行なう。
全部合わせるとこんな感じだ。
# 抽出データを1データずつに分割
df_raw = raw_data["eeg"].str.split(';', expand=True)
df_raw = df_raw.reset_index(drop=True)
df_raw
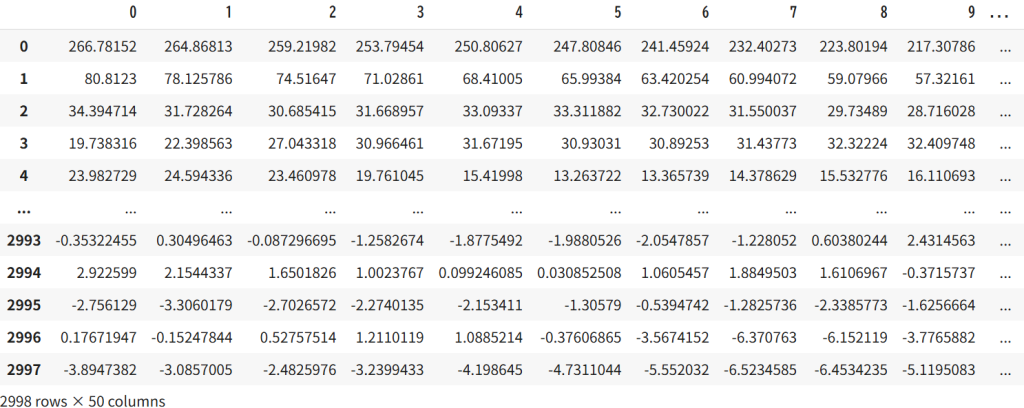
分割したものを格納した変数 “df_raw” の行数は1行ではなく、
1つの箱に格納されていたデータ数と等しい、50行となっている。
やはり1つの箱の中に50データが入っていた。
データの分割ができたので、
「1. 1つの箱に1つの数値が入っている」を満たすために、
これを1行に整列させる。
ここは結構ゴリ押しで実装している。
まずは、中身が「0」の要素をデータの数だけ用意し、それらを1列に並べた変数を用意する。
‘[ 0 ]’ で中身が 0 の箱を用意でき、これにデータ数をかけ算することでデータ数分用意できる。
データ数は ‘len(df_raw.columns)’ を用いて変数の行数を、 ‘len(df_raw)’ を用いて変数の列数を計算できる。
ここまではこんな感じで書ける。
# 分割データを1列に整列
raw_list = [0] * (len(df_raw.columns) * len(df_raw))この変数にはデータを時系列の順番に入れていきたい。
整列したいデータが格納されている変数には、
1つの列に時系列的に連続なデータが並べられている。
例えば、0行目3列目のデータの次のデータは、1行目3列目に存在する。
また、1番右端の行のデータの次のデータは、次の列の1行目に存在する。
例えば、49行目4列目のデータの次のデータは、0行目5列目に存在する。
これらのデータを 1 つずつ全て参照したい。
そこで、今回は「for文」を用いることにする。
「for文」は、変数(一般に i, j, k… などが用いられる)に、
リスト上の値を順番に代入し、リスト上の最後の値での処理が終わるまで繰り返すという手法だ。
今回は2次元データを用いるので、データ全てを巡回するには、変数が2つ必要になる。
今回は “i” と “j” を用いる事とする。
‘i’ を 0 から 50(行数)まで 1 刻みで増加させ、
‘j’ を 0 から 列数まで 1 刻みで増加させれば、
i 行目 j 列目のデータを参照することで、全てのデータを 1 回ずつ参照出来そう。
ちなみに、 i 行目 j 列目のデータは ‘df_raw[ i ][ j ]’ で表せる。
あと必要な要素としては、
- どのようにして i 行目 j 列目のデータを時系列順に参照するか
- どうやって行数や列数を取得するか
である。
i 行目 j 列目のデータを参照していくとき、どうすれば時系列順に見れるだろうか。
方法の1つとしては、まず ‘i’ を先に 1 ずつ増やしていく。
その後、右端の行までたどり着いたら、’i’ をリセットし、’j’ を 1 増やせばうまくいきそうである。
これは、「for文」で言えば、‘j’ を更新する forループの中に ‘i’ を更新する forループを入れれば実装できる。
さて、どうやって行数や列数を取得すれば良いだろうか。
ここで助けてくれるのが ‘range()’ 関数と、 ‘len()’ 関数だ。
‘range()’ は自然数を 1 つ入れると、0 から入力した自然数までの範囲の 1 刻みの数列のリストを作ってくれる関数。
‘len()’ は、変数を入れると、その変数が何行で構成されているかを自然数で返してくれる関数。
行数を表すには ‘len(df_raw)’ とすれば良く、列数を表すには ‘len(df_raw.columns)’ とすれば良い。
ここまででこんな感じ。
# 分割データを1列に整列
raw_list = [0] * (len(df_raw.columns) * len(df_raw))
for j in range(len(df_raw)):
for i in range(len(df_raw.columns)):先ほど、 ‘raw_list’ には時系列順にデータを入れていきたいと示した。
2次元データの方は i 行目 j 列目のデータは ‘df_raw[ i ][ j ]’ で時系列順にデータを取り出せる。
よって、 ‘raw_list’ に時系列順にデータを入れるには、 1 列目から順番に指定すれば良い。
つまりは、連番を作って「何番目にこの値を入れてください。」と指定する必要がある。
‘i’ と ‘j’ を用いて連番を作るにはどうしたらよいだろうか。
ここは「進数」の考え方を用いてみよう。
‘i’ が 49 から 1 増える時、’i’ は 0 にリセットされて、’j’ が 1 増える。
「進数」として考えれば、50 進数において、’i’ は 1 桁目、’j’ は 2 桁目であるといえる。
(普段使っている 10 進数の場合、一の位が 9 から 1 増える時、0 にリセットされて、十の位が 1 増える、つまり繰り上がりが起こるよね。)
つまり、’50(=行数)× j + i’ とすれば連番を表せるはずである。
‘raw_list[ len(df_raw.columns) * j + i ]’ に値を入れれば良い。
また、「2. 数値が「str型」ではなく「float型」で表されている」を満たすために、
1列にならんだ箱にデータを入れると同時に、箱に入れるデータを「float型」に変換しておく。
今回の数字以外の文字や記号(セミコロン)が入っているデータは、
「str型」という文字列を扱うことのできる型となっていて、
そのままでは数として扱うことができず、大小関係のあるデータとして解析することができない。
これを「float型」という、符号付きの小数を扱える型に変換する。
以下では、代入するデータを、関数 ‘float()’ の ( ) でくくることで、
1データずつを「float型」に変換しながら代入している。
ここまででこんな感じだ。
# 分割データを1列に整列
raw_list = [0] * (len(df_raw.columns) * len(df_raw))
for j in range(len(df_raw)):
for i in range(len(df_raw.columns)):
raw_list[len(df_raw.columns) * j + i] = float(df_raw[i][j])最後に、この後時刻データと結合することを考えて「DataFrame型」にしておこう。
行の名前を EEG としておく。
ここまでやるとこんな感じ。
# 分割データを1列に整列
raw_list = [0] * (len(df_raw.columns) * len(df_raw))
for j in range(len(df_raw)):
for i in range(len(df_raw.columns)):
raw_list[len(df_raw.columns) * j + i] = float(df_raw[i][j])
column_eeg = ["eeg"]
raw = pd.DataFrame(raw_list, columns=column_eeg)
raw
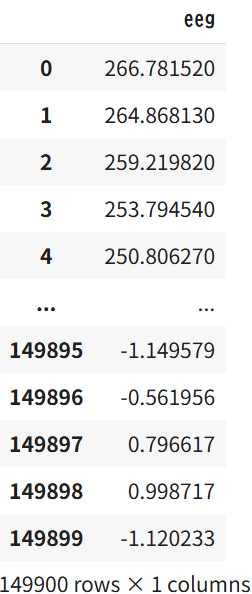
ここまでで、
- 1つの箱に1つの数値が入っている。
- 数値が「str型」ではなく「float型」で表されている。
は完了した。
次は、
3. 1つの数値に対して1つの時刻が、1対1で対応している。
を満たすために、計測時刻の整形を行なう。
抽出データの ‘Elapsed Time’ を見直してみよう。
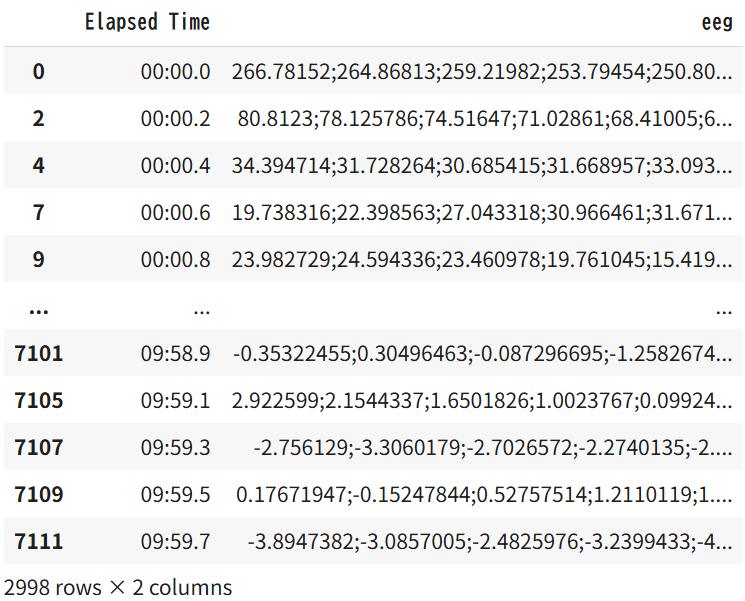
コロン (:) が用いられているのが分かるだろうか。
これは時刻が文字列、すなわち「str型」で書かれている事を示している。
「str型」は数値計算を行なうことができないため、「float型」に直そう。
コロンを残したままだと「float型」に直すことができないため、
まずはコロンによって文字列を分割しよう。
やり方は、さっきセミコロンでやったのと同様に、str.split() という関数を使えばいい。
その後、index を連番に戻すために reset_index() を行なう。
# 計測時刻を分と秒に分けて抽出
column_name = "Elapsed Time"
df_elapsedtime = raw_data[column_name]
df_elapsedtime = df_elapsedtime.str.split(':', expand=True)
df_elapsedtime = df_elapsedtime.reset_index(drop=True)
df_elapsedtime
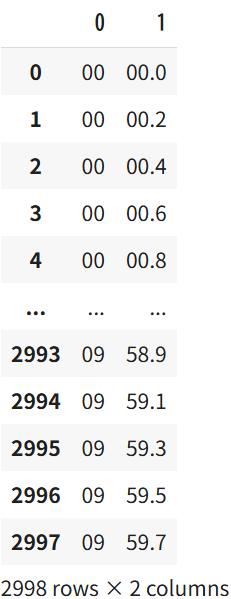
計測時刻の列数が、1 列に整列した後の EEG データの列数の
50 分の 1 程度しかないのに気づいただろうか。
これは、元々 1 列に 50 個のデータがまとまっており、
その先頭のデータしか保存されていなかったためである。
したがって、今から時刻の 1 ステップずつを 50 分割する。
ここで登場するのが、前回説明しきれなかった numpy (以下 np)である。
実は前回も用いていた ‘np.linspace()’ という関数は、
先頭の数値、末尾の数値、ステップ数をコンマ区切りで入力することで、
先頭の数値から末尾の数値までの間を、ステップ数だけに分割する 1 列の等差数列を出力してくれる。
まずは、元のデータ数の要素を持つリストを作成する。
この箱 1 つ 1 つに 50 分割したデータを入れていけば列数 × 50 の 2 次元データができる。(1 つの箱の中に 50 個の箱を入れるイメージ)
1 列ずつずらして列数回データを入力していくので、今回も for文を使えば良さそうだ。
ここまででこんな感じ
# 計測時刻を等間隔に50分割
arr_thfifHz_seconds = [0]*len(raw_data)
for i in range(len(raw_data)):次の問題は、どうやって
- 先頭の数値
- 末尾の数値
- ステップ数
を決定するか、である。
元データの ‘i’ 列目と ‘i+1’ 列目の間を 50 分割したものを、先頭から ‘i’ 番目の箱に入れれば良い。
したがって、1. 先頭の時刻には「 i 列目の時刻」を数値にしたもの、
2. 末尾の時刻には「 i+1 列目の時刻」を数値にしたものを入れれば良い。
全て単位を秒にしてしまおう。元データがstr型であることに注意し、それぞれ int型や float型に直してから 0 列目の数値を 60 倍したものを 1 列目の数値に足せばよい。
先頭の数値まで計算したものがこんな感じ
# 計測時刻を等間隔に50分割
arr_thfifHz_seconds = [0]*len(raw_data)
for i in range(len(raw_data)):
ini = 60 * int(df_elapsedtime[0][i]) + float(df_elapsedtime[1][i])しかし、末尾の数値について i+1 列目の時刻では計算できない列が存在する。
i が最後の列のとき、次の列に時刻データが無いためである。
この時だけが特殊なので、条件分岐を行なう事で回避しよう。今回は if文を用いる事にする。
if文は if(): で記述でき、()内に記述された条件(等号 (==) 、不等号 (<, <=, >=, >) を用いる)を満たす場合にのみ、続くコードの内容を実行するものである。
if文には if(): の他にも、
今回は使わない elif(): ( if の()内の条件は満たさないが、elif の()内の条件を満たすなら実行)や、
else: ( if の()内の条件も、elif の()内の条件も満たさない場合に実行)もある。
今回は i == (最後の列) であるときだけ条件付けし、残りは else にまとめてしまおう。
最後の列は ‘len(df_elapsedtime) – 1’ で計算できる。
では、この特殊な条件のときに末尾の数値をどう決定しようか。
今回は FocusCalm™ の性能から決めようと思う。
GoodBrain の FocusCalm™ のページにアクセスし、「他のデバイスとの比較」を見てみると、
- 脳波の生データ(約250Hz)
とある。
250 Hz で 50 データ取得するには、0.2 秒 (1/5 秒) かかるはずなので、
最後の列の末尾の数値は、先頭の数値に 0.2 を足したものとしよう。
ここまででこんな感じになる。
# 計測時刻を等間隔に50分割
arr_thfifHz_seconds = [0]*len(raw_data)
for i in range(len(raw_data)):
ini = 60 * int(df_elapsedtime[0][i]) + float(df_elapsedtime[1][i])
if (i == (len(df_elapsedtime) - 1)):
fin = ini + 0.2
else:
fin = 60 * int(df_elapsedtime[0][i+1]) + float(df_elapsedtime[1][i+1])あとはステップ数を決定すれば良い。ステップ数は、先頭と末尾の数値を含めた分割するための数値の個数なので、等間隔に 50 分割したい場合のステップ数は 51 となる。
あとは ‘np.linspace(ini, fin, 51)’ を用意したリストの要素 1 つ 1 つに入れていけばよい。
最終的にこんな感じ。
# 計測時刻を等間隔に50分割
arr_twhunfifHz_seconds = [0]*len(raw_data)
for i in range(len(raw_data)):
ini = 60 * int(df_elapsedtime[0][i]) + float(df_elapsedtime[1][i])
if (i == (len(df_elapsedtime) - 1)):
fin = ini + 0.2
else:
fin = 60 * int(df_elapsedtime[0][i+1]) + float(df_elapsedtime[1][i+1])
arr_twhunfifHz_seconds[i] = np.linspace(ini, fin, 51)
そもそもどうして時刻を 50 分割したかというと、EEG データとの 1 対 1 対応を作るためである。
つまり、これも 1 列に並べなければならない。
先ほどと同様に、2 重の for文を使えば良いのだが、1 つ問題がある。
リストを内包するリストは、先ほど整列したデータと行と列が入れ替わっているのである。
つまり、先ほどと全く同じ書き方をすると、順番通りに代入することができないのである。
そのため、今回は代入するデータを指定するための ‘i’ と ‘j’ のみを入れ替える。
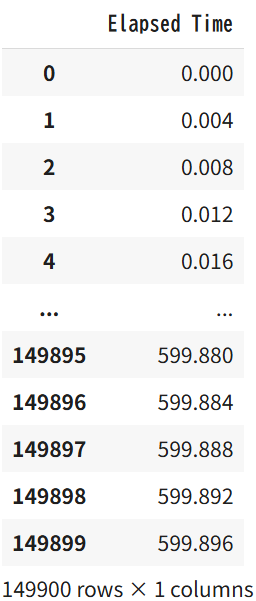
# 時間データを1列に整列
twhunfifHz_seconds = [0] * (len(raw_list))
for j in range(len(arr_twhunfifHz_seconds)):
for i in range(50):
twhunfifHz_seconds[50 * j + i] = float(arr_twhunfifHz_seconds[j][i])
column_name = ["Elapsed Time"]
df_twhunfifHz_seconds = pd.DataFrame(twhunfifHz_seconds, columns=column_name)
df_twhunfifHz_seconds
最後に、秒数を「分:秒.ミリ秒」の形に直して分かりやすくしよう。
Pythonにおいては、’//’ で割り切り、’%’ で余りを計算できる。
str型でないとコロン (:) を使えないことに注意しよう。str型は ‘+’ で連結できるぞ。
# 秒数を分:秒.ミリ秒に直す
for i in range(len(raw_list)):
if int(twhunfifHz_seconds[i]%60) < 10:
twhunfifHz_seconds[i] = "0" + str(int(twhunfifHz_seconds[i])//60) + ":0" + str(round(twhunfifHz_seconds[i]%60, 3))
else:
twhunfifHz_seconds[i] = "0" + str(int(twhunfifHz_seconds[i])//60) + ":" + str(round(twhunfifHz_seconds[i]%60, 3))
# column_name = ["Elapsed Time"]
twhunfifHz_time = pd.DataFrame(twhunfifHz_seconds, columns=column_name)
twhunfifHz_time
これで、生の波形データ(記録した電位)と 1 対 1 で対応する計測時刻のデータを作成できた。
先ほど作成した 1 列の生の波形データと、今作成した 1 列の計測時刻を結合すれば、
3. 1つの数値に対して1つの時刻が、1対1で対応している。
を達成できる。
というわけで先ほどの 2 つのデータを結合してみよう。
やり方は簡単で、’pd.concat()’ という関数を用いるだけ。
‘axis=1’ は行を増やすように結合することを示している。
左に来て欲しい行から順に、カンマ( , )で分け、[ ]で結合したい変数全体を囲んで入力しよう。
# 時間と生波形の1対1対応をまとめる
raw = pd.concat([twhunfifHz_time, raw], axis=1)
raw
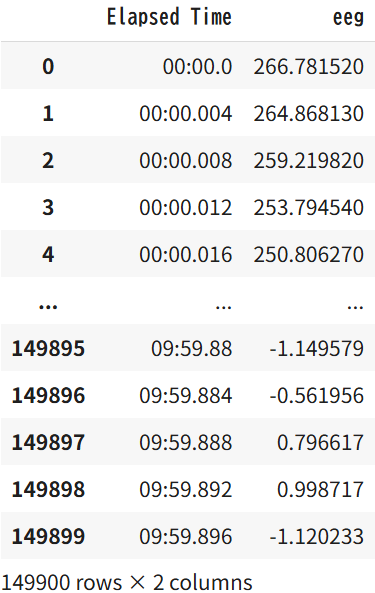
今回もデータを折れ線グラフで描画してみよう。
描画
ここからは matplotlib(以下 plt)をつかって描画していくよ。
fig, ax = plt.subplots()
として、描画スペースを ‘fig’ と ‘ax’ に確保する。
‘fig’ は描画スペース全体で、’ax’ はその中でも実際にグラフを書く場所っていうイメージ。
ax.set_xlabel("「具体的な x 軸の名前」")
で x 軸の名前を設定。
ax.set_ylabel("「具体的な y 軸の名前」")
で y 軸の名前を設定。
ax.set_xticks(np.linspace(0, len(「用いるデータの変数名」)-1, 10))
で x 軸の目盛を設定。
plt.xticks(rotation=15)
で x 軸の目盛を 15°回転させて、時刻の表記が被らないように回転させて調節。
ax.plot(「x 軸に用いるデータ」, 「y 軸に用いるデータ」, color='「色の名前」')
で、折れ線グラフを描画。
fig.tight_layout()
で、図のレイアウト(余白の大きさなど)を設定。
plt.show()
で、図を出力。
今回は「y 軸に用いるデータ」を先に変数 ‘y’ に代入した。
fig, ax = plt.subplots()
y = raw['eeg']
ax.set_xlabel("時間(分:秒.ミリ秒)")
ax.set_ylabel("脳波")
ax.set_xticks(np.linspace(0, len(raw)-1, 10))
plt.xticks(rotation=15)
ax.plot(raw['Elapsed Time'], y, color='black')
fig.tight_layout()
plt.show()

これだと良く分からないので、20 秒ぐらいの幅でズームしてみよう。
とりあえず描画の開始点を ‘c’ に代入しよう。
‘c’ から 20 秒分のデータを ‘cutted’ に代入したい。
脳波データの取得は約 250 Hz だったので、 20 * 250 データがあれば 20 秒分になる。
今回は縦軸に制限を設ける。
最大値と最小値は ‘ax.set_ylim()’ で設定できる。
今回は -60 以上 60 以下とするので、 ‘ax.set_ylim(-60, 60)’ とする。
fig, ax = plt.subplots()
c = len(raw)//5
cutted = raw[c : c + 20 * 250]
y = cutted['eeg']
ax.set_xlabel("時間(分:秒.ミリ秒)")
ax.set_ylabel("脳波")
ax.set_xticks(np.linspace(0, len(cutted)-1, 10))
ax.set_ylim(-60, 60)
plt.xticks(rotation=15)
ax.plot(cutted['Elapsed Time'], y, color='black')
fig.tight_layout()
plt.show()
上手く描画できたかな?
実は EEG は低振幅・高周波数、つまり小さく細かくギザギザしている成分なんです。
そのため、めちゃくちゃノイズの影響を受けやすいんです。
終わりに
今回は前回触れられなかった EEG の描画を、 Python でやってみました。
楽しんでもらえましたか?
脳波を解析する事に関しては、まだまだこれで終わりじゃないです。
特定周波数の指標ってなんなんでしょう。集中度やリラックス度はどのように計算されているのでしょうか。
もっと脳波に触れて、プログラミングを触って、楽しみながら探究してみてください!
おまけ
今回のデータを取得するのに使用した FocusCalm™ の情報を載せておきます。
これを見て「脳波計測やってみたいかも…」って思ったそこのあなた、ぜひ一度体験してみてください!
脳波デバイスの情報はこちら!
※最後に、完成版のColabファイルを閲覧できるようにしておきます。
完成版Colabファイル: https://colab.research.google.com/drive/1PHETB_pjDq5vrv3I0kisR5pr2UFkTcPp?usp=sharing