
GBアプリをインストールした!脳波計測に興味がある!実際に FocusCalm™ で測ってみてファイルを出力してみた!
…でも、“.csv” ってどうやって開くの…?中身を見れたのはいいけど、数字ばっかで訳わかんない…
そんなあなたへ!「分からない」で諦めて欲しくないから、Python というプログラミング言語を用いた解析方法をお教えします!
まだ脳波計測したことないよって方も、この機会に是非、一度触れてみてください!
目次
本日の目標
GoodBrainアプリから出力したCSVファイルを、自分で描画してみよう!
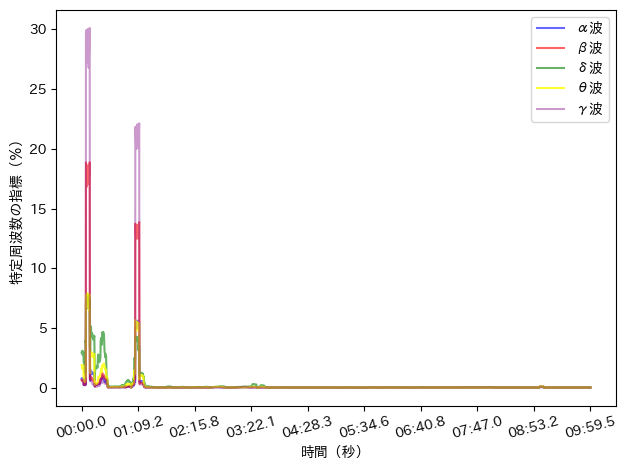
上手くいくとこんな感じの画像が出力できます!
今回利用するツール
本日の主役
Python
現在最もメジャーで最も簡単な言語。なにより使いやすいのが特徴。また、いろんな人が使いやすくするための拡張機能(ライブラリ)を制作してるから、初心者でも超扱いやすい!
Pythonをサポートする、イカしたメンバー(ライブラリ)を紹介するぜ!!!
Numpy
Pythonが数学につよつよになるライブラリ。今回は数列を作成するのに用いる。
Pandas
表データを扱いやすくなるライブラリ。今回はCSVファイルの読み込みと、データの整形に用いる。
Matplotlib
データの描画を行なうライブラリ。今回は折れ線グラフを画像ファイル形式で出力するのに用いる。
補足:japanize_matplotlib
Matplotlibで図を出力する際、ラベル名に日本語を用いると文字化けしてしまう。これを解消するためのライブラリ。プログラミングって基本的に英語だからね…日本語対応してる方が珍しいんだよね…仕方ないね…
初めての方におすすめのPython実行環境はコレ!
Google Colaboratory
ブラウザ上でコードを作成することで、Googleのサーバで計算することのできるアプリケーション。お手軽で、Google側のマシンを用いるため比較的高速に動作する。上で述べたライブラリのうち、Numpy、Pandas、Matplotlibは初期環境の時点でインストールされている。まあ、簡単に言えば、Googleにコンピュータを貸してもらって、それを遠隔操作するって感じ。
そんなわけで、今回はGoogle Colaboratoryで実装していきます。
多分これが一番お手軽だと思います。
Google Colaboratoryの開き方
- Googleアカウントを用意する。
新規アカウントを作成しても、既存アカウントを利用してもどっちでもOK。お好きな方で。 - Googleドライブを開く。
https://www.google.co.jp/ にアクセスし、下図の矢印の先のマークから、“ドライブ” を選択。 - Google Colaboratoryを開く。
Googleドライブの “新規” から “Google Colabolatory” を選択。
もし、“その他” の中にも見つからない場合は、 “その他” > “アプリを追加” を選択。
検索ボックスに “google colab” と入力して、“Colabolatory”をインストール。 - ドライブの “新規” から “Google Colabolatory”を選択すると、以下のような画面が表示される。ここにコードを記述することで、Google Colaboratoryを利用できる。



あとは灰色の「セル」ってやつに、コードを書き込んだりテキストで説明を入れたりすればOK。
Google Colaboratoryの使い方
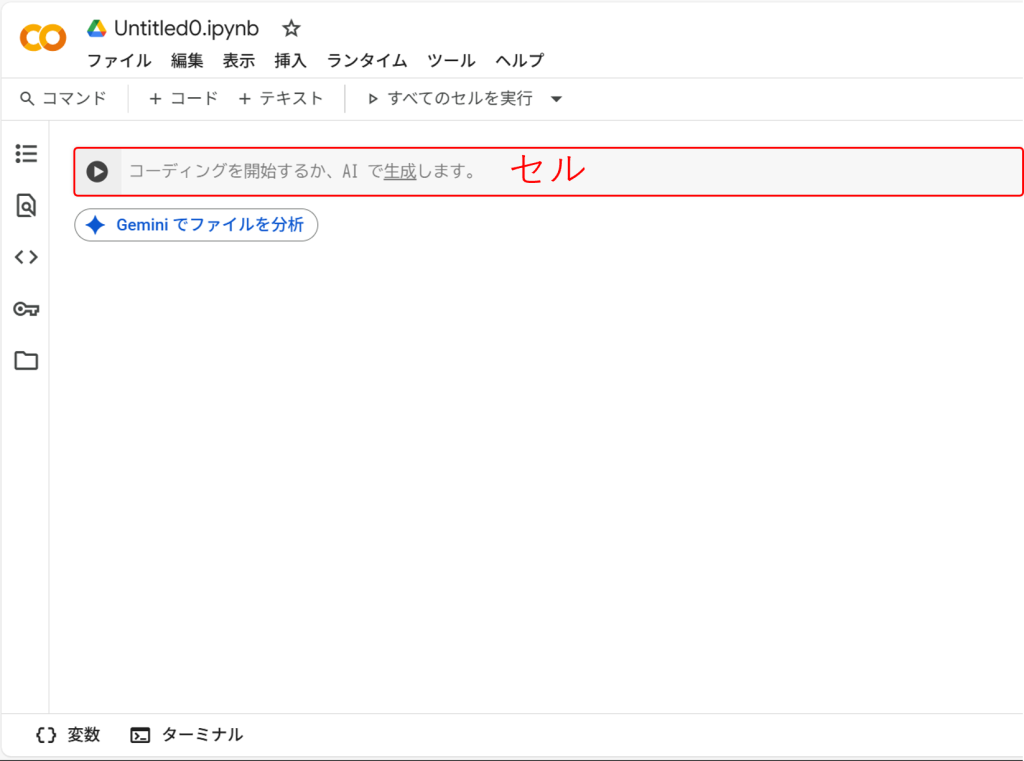
文が書いてあったり、コードが書かれたりする場所は「セル」って名前。
セルは、セルの間や上下にマウスポインタを合わせたときに出てくる「+コード」や「+テキスト」をクリックしたり、上のホットバーにある「挿入」をクリックしてから、「コードセル」や「テキストセル」をクリックすることで追加できる。
コードセルは、実行することができる。
実行しなければ、コンピュータ側はプログラムの内容を反映してくれない。
Google Colaboratoryではセルを分けて記述することで、コードを段階的に記述し、独立に実行することができる。こまめに実行することで、コードに不備がないか確認しよう。
コードセルの実行方法だが、
セルの1番左にある “[ ]” にカーソルを合わせると、右向きの三角形になるので、これをクリックする。
または、ショートカットで実行することもできる。
Windowsの人は、セルをクリックして「Ctrl」+「Enter」
Macの人は、セルをクリックして「Cmd」+「Enter」
である。
セルを実行しながら次のセルに移るには、
Windows / Mac 共通で「Shift」+「Enter」
である。
ライブラリの準備
先述の通り、Google ColaboratoryにはNumpy、Pandas、Matplotlibがすでにインストールされているため、japanize_matplotlibのインストール方法を説明する。
セル内に
! pip install japanize_matplotlibと記述する。
もしくは、
Google Colaboratoryのターミナルに
pip install japanize_matplotlibと打ち込む。
何をしてるかというと、「pip 君、install してくれ japanize_matplotlib を」って感じ。そのまんまだね。
※ちなみに pip っていうのは、Python関連に対して、ライブラリをインストールしたり、バージョン指定したりする管理者ってイメージ。

pipさん
「このライブラリ、
インストールして使えるようにしとくね」
「今どんなライブラリがインストールされてるかって?
はい、これ一覧ね
それぞれのバージョンもつけといたよ」
「pandas ってどんなのかって?
データ統計のためのパワフルなデータ構造を
追加するやつだよ」
「お、ライブラリのアップデートする?
インストールまでやっとくね」
「Pythonのアップデート?
了解、Python公式ページにアクセスして、
インストールまでやっとくね」
先のコードを実行すると長い文字列が表示される。

Successfully installed japanize_matplotlib-“バージョン( ‘1.1.3’ など)”
と表示されればインストール完了!
ただし、インストールされているだけでは、その機能を使うことはできない。
次は、numpy, pandas, matplotlib, japanize_matplotlibを、実際に使えるようにする必要がある。”import” を用いて、利用できるようにしよう。
インストールは、その機械にライブラリを覚えさせるイメージ、
“import” は、コード中でそのライブラリを使うことを許可するイメージ。
# 必要なライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
データの読み込み(ファイルのアップロード方法から)
ランタイムに接続後、ドラッグアンドドロップで簡単にファイルをアップロードできる。ランタイムに接続する方法としては、ホットバーの “ランタイム” から接続するか、コードを記述したセルを実行。

ドラッグアンドドロップして、ファイルのアップロードが完了したら、アップロードしたCSVファイルをコード内に読み込ませよう。
プログラミングにおいては、使うデータを「変数」と呼ばれる格納庫に記憶させておく必要がある。今回は “df” ( ‘DataFrame’ という構造型の略)という変数にしまっておくことにする。
pandas(以下 pd )の read_csv() という関数を用いることで、CSVファイルの読み込みができる。read_csv() の () の中には、先ほどドラッグアンドドロップしたファイル名を入れよう。
# GoodBrainアプリから出力したCSVファイルを、DataFrame型というデータ構造に入れる。
df = pd.read_csv("「実際にアップロードしたファイル名」")
df
セルの最後の行に変数名を入力すると実行結果が表示される。
それがCSVファイルの中身。
‘TimeStamp’ は計測した際の実際の時間、
‘Elapsed Time’ は計測開始からの時刻、
‘alpha’ から ‘gamma’ は各特定周波数の指標、
‘eeg’ は生波形と呼ばれる電位の実測値、
‘attention’ は集中度の指標、
‘meditation’ はリラックス度の指標、
をそれぞれ表している。
今回は「各特定周波数の指標」と「集中度・リラックス度の指標」を解析していく。
ただ、問題として、NaN と表記される、数値の入っていないところがある。
このままでは解析することができないので、解析の前にデータの整形を行なう。
特定周波数データの解析
まずは、アルファ波、ベータ波といった、特定周波数の割合のデータを整形してみよう。
特定周波数の1つ、アルファ波の割合は ‘df’ 内の ‘alpha’ 行のデータである。
下のコードでやっていることを順番に説明する。
- 変数を用意し(今回は “a” )、そこにloc[ ]を用いて元のデータ(’df’)のうちの欲しい部分(今回は計測時刻 ‘Elapsed Time’ と、アルファ波 ‘alpha’ の行)を持ってくる。
- NaN が含まれる列を、dropna() で削除する。
- dropna() を使うと表の一番左の行にある index が連番じゃなくなるので、reset_index(drop=True) をすることで、index をリセットして連番にする。
# アルファ波の抽出
a = df.loc[:, ['Elapsed Time', 'alpha']]
a = a.dropna()
a = a.reset_index(drop=True)
a
これでこのまま解析できるデータになった。
他のベータ波やデルタ波も同じようにやってみよう。
- 変数を用意して、loc[ ] で欲しいデータを取り出す
- dropna() で NaN を削除
- reset_index() で連番に直す
# ベータ波の抽出
b = df.loc[:, ['Elapsed Time', 'beta']]
b = b.dropna()
b = b.reset_index(drop=True)
# b# デルタ波の抽出
d = df.loc[:, ['Elapsed Time', 'delta']]
d = d.dropna()
d = d.reset_index(drop=True)
# d# シータ波の抽出
th = df.loc[:, ['Elapsed Time', 'theta']]
th = th.dropna()
th = th.reset_index(drop=True)
# th# ガンマ波の抽出
g = df.loc[:, ['Elapsed Time', 'gamma']]
g = g.dropna()
g = g.reset_index(drop=True)
# gベータ波、デルタ波、シータ波、ガンマ波までできたら、特定周波数のデータの整形は完了。お楽しみの解析タイムいってみよう!
解析、といっても初めてなので、直感的に分かりやすい方法でやってみようと思う。
というわけで、今回はデータを折れ線グラフで描画してみよう。
ここからは matplotlib(以下 plt)をつかって描画していくよ。
fig, ax = plt.subplots()
として、描画スペースを ‘fig’ と ‘ax’ に確保する。
‘fig’ は描画スペース全体で、’ax’ はその中でも実際にグラフを書く場所っていうイメージ。
ax.set_xlabel("「具体的な x 軸の名前」")
で x 軸の名前を設定。ax.set_ylabel("「具体的な y 軸の名前」")
で y 軸の名前を設定。ax.set_xticks(np.linspace(0, len(「用いるデータの変数名」)-1, 10))
で x 軸の目盛を設定。plt.xticks(rotation=15)
で x 軸の目盛を 15°回転させて、時刻の表記が被らないように回転させて調節。
ax.plot(「x 軸に用いるデータ」, 「y 軸に用いるデータ」, color='「色の名前」')
で、折れ線グラフを描画。
fig.tight_layout()
で、図のレイアウト(余白の大きさなど)を設定。
plt.show()
で、図を出力。
今回は「y 軸に用いるデータ」を、先に変数 ‘y1’ から ‘y5’ に代入しておいた。
「色の名前」は ‘c1’ から ‘c5’ に代入した。
また、今回は、複数のグラフを同じ ‘ax’ で出力するので、凡例(legend)を出力する。
凡例での名前を ‘l1’ から ‘l5′ に代入し、’ax.plot()’ の際に、’label=’ に入力、
透明度を調節する ‘alpha=’ に 0 から 1 までの任意の数を入力し、
‘ax.legend(loc=0)’ で凡例を出力した。
実際のコードがこんな感じ。
fig, ax = plt.subplots()
y1 = a['alpha']
y2 = b['beta']
y3 = d['delta']
y4 = th['theta']
y5 = g['gamma']
c1, c2, c3, c4, c5 = "blue", "red", "green", "yellow", "purple"
l1, l2, l3, l4, l5 = "α波", "β波", "δ波", "θ波", "γ波"
ax.set_xlabel("時間(秒)")
ax.set_ylabel("特定周波数の指標(%)")
ax.set_xticks(np.linspace(0, len(a)-1, 10))
plt.xticks(rotation=15)
ax.plot(a['Elapsed Time'], y1, color=c1, label=l1, alpha=0.6)
ax.plot(b['Elapsed Time'], y2, color=c2, label=l2, alpha=0.6)
ax.plot(d['Elapsed Time'], y3, color=c3, label=l3, alpha=0.6)
ax.plot(th['Elapsed Time'], y4, color=c4, label=l4, alpha=0.8)
ax.plot(g['Elapsed Time'], y5, color=c5, label=l5, alpha=0.4)
ax.legend(loc=0)
fig.tight_layout()
plt.show()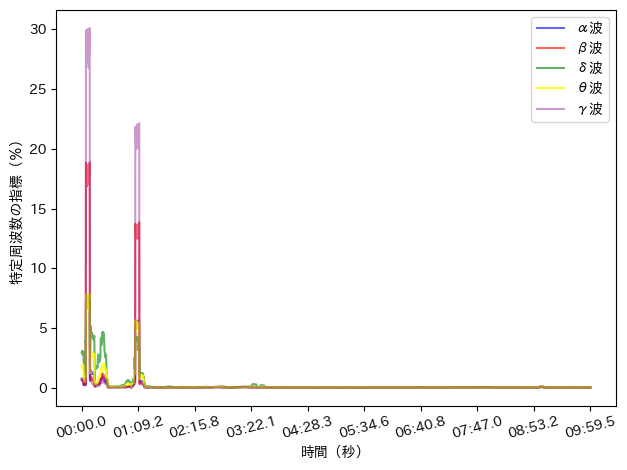
これでグラフが描画できた!
集中度とリラックス度についても同じようにやってみよう。
集中度とリラックス度の解析
集中度とリラックス度の指標もデータの整形からやってみよう。
まずは集中度から。
特定周波数のときと同様に、
- 変数を用意して、loc[ ] で欲しいデータを取り出す
- dropna() で NaN を削除
- reset_index() で連番に直す
をやってみよう。
# 集中度の抽出
att = df.loc[:, ['Elapsed Time', 'attention']]
att = att.dropna()
att = att.reset_index(drop=True)
att
リラックス度も同様、
- 変数を用意して、loc[ ] で欲しいデータを取り出す
- dropna() で NaN を削除
- reset_index() で連番に直す
をやってみよう。
# リラックス度の抽出
med = df.loc[:, ['Elapsed Time', 'meditation']]
med = med.dropna()
med = med.reset_index(drop=True)
med
列の数がそろっているので、そのまま結合してみよう。
今回はどちらのデータにも同じ指標である「計測時刻(Elapsed Time)」が含まれているので、それを基準に結合してみる。
‘pd.marge()’ という関数を使ってみよう。
下に書くコードの、
” on=’Elapsed Time’ ” は計測時刻を基準に結合することを示す。
” how=’outer’ ” は基準の指標に共通していないデータがあっても、全てのデータを残し、穴あきには NaN を入れておく事を示す。
‘pd.marge()’ の場合は、左に乗せたいデータから順に、変数をカンマ( , )で分けて入力すればOK。
” how=’outer’ ” の説明で述べたように、基準の指標に共通していないデータがある場合、そのデータを残して結合する。その場合、どのように結合されるかというと、右に入力されたデータ中に、基準の指標で共通していないデータが見つかった場合に、最も下の列に追加されていく。
つまりは、「計測時刻順に並んでいることを保証できない」ということになる。そのため、’sort_values()’ 関数を用いて、計測時刻(Elapsed Time)順に並べ替えよう。
# 集中度とリラックス度の結合
attmed = pd.merge(att, med, on='Elapsed Time', how='outer').sort_values('Elapsed Time')
attmed
列数が増えてしまった事にお気づきだろうか。計測の際にどこかで保存時刻がズレてしまい、” how=’outer’ ” によって NaN が入れられているということである。
NaN をなくすために、もっともらしい数値で置き換えよう。
幸いなことに、1 列目に NaN が入っていないため、今回は NaN を同じ行の 1 つ上の列の値で置き換える事にする。’ffill()’ 関数を使えば一発だ。
attmed = attmed.ffill()
attmedやっとデータを整理することができた。
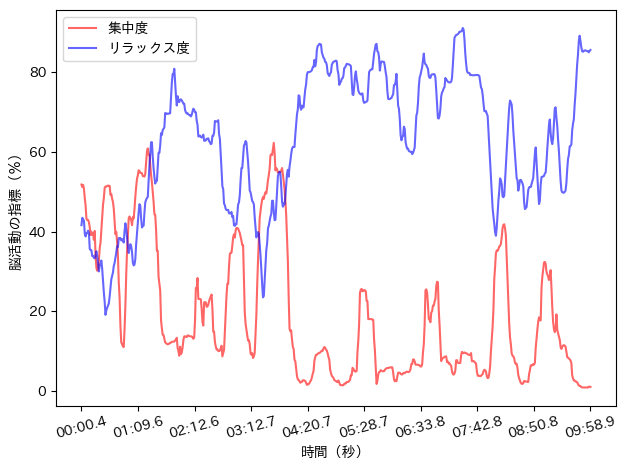
それじゃ、お待ちかねの「描画」タイム、いってみよう!
描画の仕方をもう一度説明していくね。
fig, ax = plt.subplots()
として、描画スペースを ‘fig’ と ‘ax’ に確保する。
‘fig’ は描画スペース全体で、’ax’ はその中でも実際にグラフを書く場所っていうイメージ。
ax.set_xlabel("「具体的な x 軸の名前」")
で x 軸の名前を設定。ax.set_ylabel("「具体的な y 軸の名前」")
で y 軸の名前を設定。ax.set_xticks(np.linspace(0, len(「用いるデータの変数名」)-1, 10))
で x 軸の目盛を設定。plt.xticks(rotation=15)
で x 軸の目盛を 15°回転させて、時刻の表記が被らないように回転させて調節。
ax.plot(「x 軸に用いるデータ」, 「y 軸に用いるデータ」, color='「色の名前」')
で、折れ線グラフを描画。
fig.tight_layout()
で、図のレイアウト(余白の大きさなど)を設定。
plt.show()
で、図を出力。
今回もデータが複数あるので、
‘label=’ に凡例での名前を入力し、
‘ax.legend(loc=0)’ で凡例を表示しよう。
実際のコードがこんな感じ。
fig, ax = plt.subplots()
ax.set_xlabel("時間(秒)")
ax.set_ylabel("脳活動の指標(%)")
ax.set_xticks(np.linspace(0, len(attmed)-1, 10))
plt.xticks(rotation=15)
ax.plot(attmed['Elapsed Time'], attmed['attention'], color="red", label="集中度", alpha=0.6)
ax.plot(attmed['Elapsed Time'], attmed['meditation'], color="blue", label="リラックス度", alpha=0.6)
ax.legend(loc=0)
fig.tight_layout()
plt.show()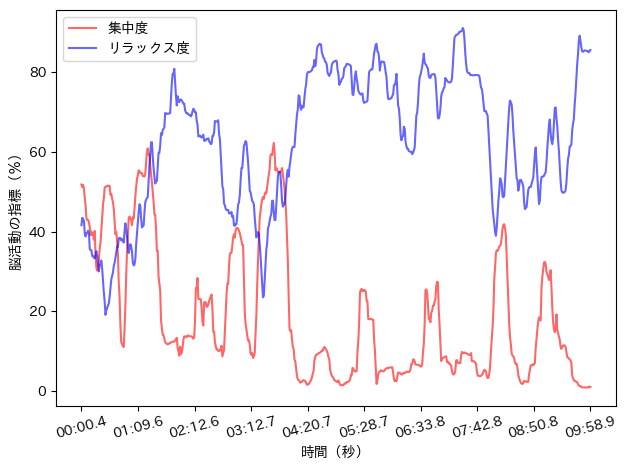
集中度・リラックス度の方も描画できたね。
お疲れ様でした。
終わりに
特定周波数の方も、集中度やリラックス度の方も、無事に出力できたかな?
今回はPython を使って、脳波解析のための「描画」をやってみました。
楽しんでもらえましたか?
脳波を解析する事に関しては、まだまだこれで終わりじゃないです。
実際、今回のデータの ‘eeg’ は描画してませんし、解析方法も描画だけじゃありません。
もっと脳波に触れて、プログラミングを触って、楽しみながら探究してみてください!
※最後に、完成版のColabファイルを閲覧できるようにしておきます。
完成版Colabファイル:https://colab.research.google.com/drive/10nShwtn0TVDS27se9ALlx51JtrVzcwCV?usp=sharing